
In het AI tijdperk bepaalt Data Lifecycle hygiëne de kwaliteit van de reacties
Copilot weet niet dat je spreadsheet drie jaar oud is. Dat is jouw probleem om op te lossen. Een praktische kijk op retentie en waarom dispositie een zakelijke beslissing is, geen IT-taak.

Dit is onderdeel van een reeks artikelen over Data Security en waarom AI ons dwingt onze aanpak aan te passen. Eerder schreef ik dat de verschuiving die GenAI introduceert niet technisch is, maar gedragsmatig. Wat vroeger vindbaar was, werd vraagbaar: wat vroeger intentie en inspanning vereiste, is nu één goed geformuleerde vraag verwijderd. We zien dat vertrouwelijkheid in de loop van de tijd afdrijft en door evoluerend deelgedrag lijken we de toegang los te maken van de intentie. We hebben de Data Security-kant diepgaand besproken, gaan nu de Data Quality-kant verkennen: niet wat het blootlegt, maar wat het uit het verleden opduikt.
Als je de vorige posts hebt gemist, raad ik je ten zeerste aan om ze te lezen:
Data en AI: waarom GenAI-oplossingen oude auditbevindingen omzetten in het risico van vandaag
Vertrouwelijkheid drift: een verborgen risico Copilot maakt onmogelijk te negeren
Gegevensbescherming die werkt, waardoor AI veilig kan worden ingeschakeld
Hoe te voorkomen dat GenAI verwerkt wat het niet zou moeten doen
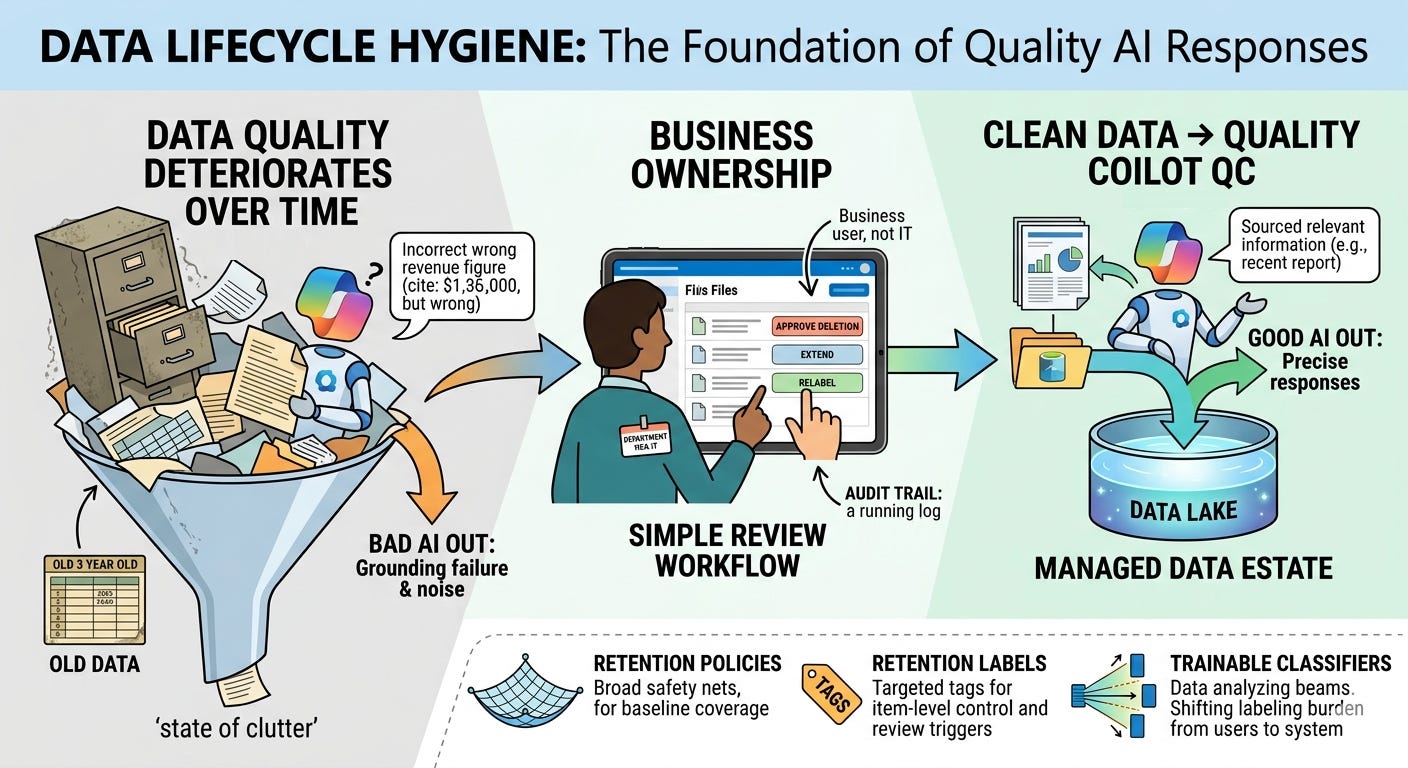
Oude spreadsheets blijven bestaan, worden gekopieerd en worden vaak het gemakkelijkste om te vinden. Copilot ground op wat beschikbaar en toegankelijk is. Daarom is lifecycle management niet alleen compliance, het is Copilot-kwaliteitscontrole.
Bedenk wat dat in de praktijk betekent. Wanneer een collega Copilot vraagt om de omzetcijfers van vorig kwartaal, grijpt het niet instinctief naar het meest recente dossier. Het reikt naar de meest toegankelijke. Dat kan een 3 jaar oude spreadsheet zijn die iemand heeft geüpload naar zijn OneDrive- of Teams-map. Copilot zal het met vertrouwen gebruiken, duidelijk citeren en de resultaten presenteren alsof ze actueel zijn.
Dit is geen Copilot-storing, elke andere GenAI-oplossing zal hetzelfde werken en hebben allemaal hetzelfde basisprincipe. Je data estate is de gouden bron. Hoewel je dit kunt oplossen met prompt engineering, is het een probleem in je data-estate.
Waarom dit er nu toe doet
Data lifecycle management is de discipline van het regelen van informatie van creatie tot verwijdering en bestaat al tientallen jaren. Het heeft compliance teams altijd blij gemaakt. Het heeft er zelden voor gezorgd dat iemand anders er warm of koud van wordt - althans, als ik over mezelf praat kijkend naar de vele klanten waar ik het plezier heb gehad om hieraan te werken.
AI verandert die vergelijking echter. Traditionele business intelligence-tools vereisten menselijke analisten die oordeel konden toepassen, oude input konden vangen en de alom belangrijke “is dit de juiste versie?” vraag stellen. Copilot mist dat filter. Het synthetiseert wat het ook vindt. We gaan weg van de traditionele “Garbage In, Garbage Out“ naar een nieuwe “Bad Data In, Bad AI Out” - hetzelfde risico, nu onbeheerd op machinesnelheid.
Het gevolg van slecht levenscyclusbeheer was vroeger een compliance bevinding op zijn best een opslagkosten probleem. Nu is het een zelfverzekerd, plausibel, verkeerd antwoord geleverd op machinesnelheid, aan iedereen die durft te vragen. Het opruimen van ROT (Redundant, Verouderde, Triviale inhoud) en het afdwingen van verstandige retentie is geen achtergrondtaak meer. Het is de kwaliteitscontrolelaag geworden voor AI-oplossingen.
Eigenaarschap vanuit de business is niet optioneel
Voordat we in de technische oplossingen duiken, zoals alle goede consultants de neiging hebben om te doen. Dit is het onderdeel dat de meeste implementaties van de levenscyclus verkeerd zijn. IT ontwerpt de beleidsstructuur, configureert hun tooling naar keuze (bijv. Purview), traint de classifiers, en verwacht dan dat het bedrijf rustig zal profiteren. Wanneer de verwijderingen arriveren, probeert IT ze te beheren. Het bedrijf klaagt over het emails die verwijdering aankondingen die ze niet begrijpen. Niets wordt goedgekeurd. Bewaartermijnen worden voor onbepaalde tijd verlengd. De rommel blijft.
De reden is eenvoudig: IT weet niet wat de inhoud betekent. Een recordsmanager die een lijst bekijkt met bestanden die in SharePoint verlopen, kan je niet vertellen of het inkoopteam die leveranciersovereenkomsten nog steeds nodig heeft, of dat het projectteam die planningsdocumenten heeft vervangen. Alleen de mensen die met de data werken kunnen hier antwoord op geven.
Dispositie review workflows bestaan precies om die beslissing in de juiste handen te leggen. Wanneer een bewaarlabel zijn einddatum bereikt, ontvangen beoordelaars een melding. Wie zijn de aangewezen reviewers? Ze worden geselecteerd uit de betreffende business unit, en IT vergemakkelijkt dit door ze op de juiste manier toe te wijzen. Beoordelaars zien de items die op hun oordeel wachten, ze kunnen een voorbeeld van de inhoud bekijken en een expliciete beslissing nemen: verwijderen, verlengen, opnieuw labelen of escaleren goedkeuren. Elke actie wordt gelogd met een tijdstempel naast de identiteit van de reviewer.
Het auditspoor dat dit creëert is belangrijk. Wanneer een toezichthouder vraagt hoe je een bepaalde categorie record hebt beheerd, kunt je precies laten zien wie het heeft beoordeeld en wanneer. Wanneer een bedrijfsonderdeel beweert dat een document foutief is verwijderd, kan je de goedkeuring tonen.
Mijn advies: Laat levenscyclus niet veranderen in een IT-only opruimproject. Maak het bedrijf verantwoordelijk voor dispositiebeslissingen en geef ze vervolgens mechanismen om die beslissingen praktisch te maken. Dat betekent het toewijzen van reviewers die de inhoudscategorie begrijpen, niet de dichtstbijzijnde compliance officer. Het betekent het vooraf inplannen van beoordelingscycli, zodat bedrijfsonderdelen niet verrast zijn door vervalaanzeggingen. En het betekent dat de beoordelingsinterface eenvoudig genoeg is dat een afdelingshoofd door hun wachtrij kan werken zonder IT-ondersteuning. De workflow is slechts zo goed als de participatie die het genereert.
The Retention toolkit
Op naar de techniek! De Data Lifecycle Management-mogelijkheden van Microsoft Purview geven je de bouwstenen om dit goed te doen. Begrijpen waar elke tool past is essentieel voordat je begint met het configureren van iets. Een snelle herinnering voor iedereen die niet bekend is met de oplossingen en terminologie die binnen het Microsoft-ecosysteem worden gebruikt.
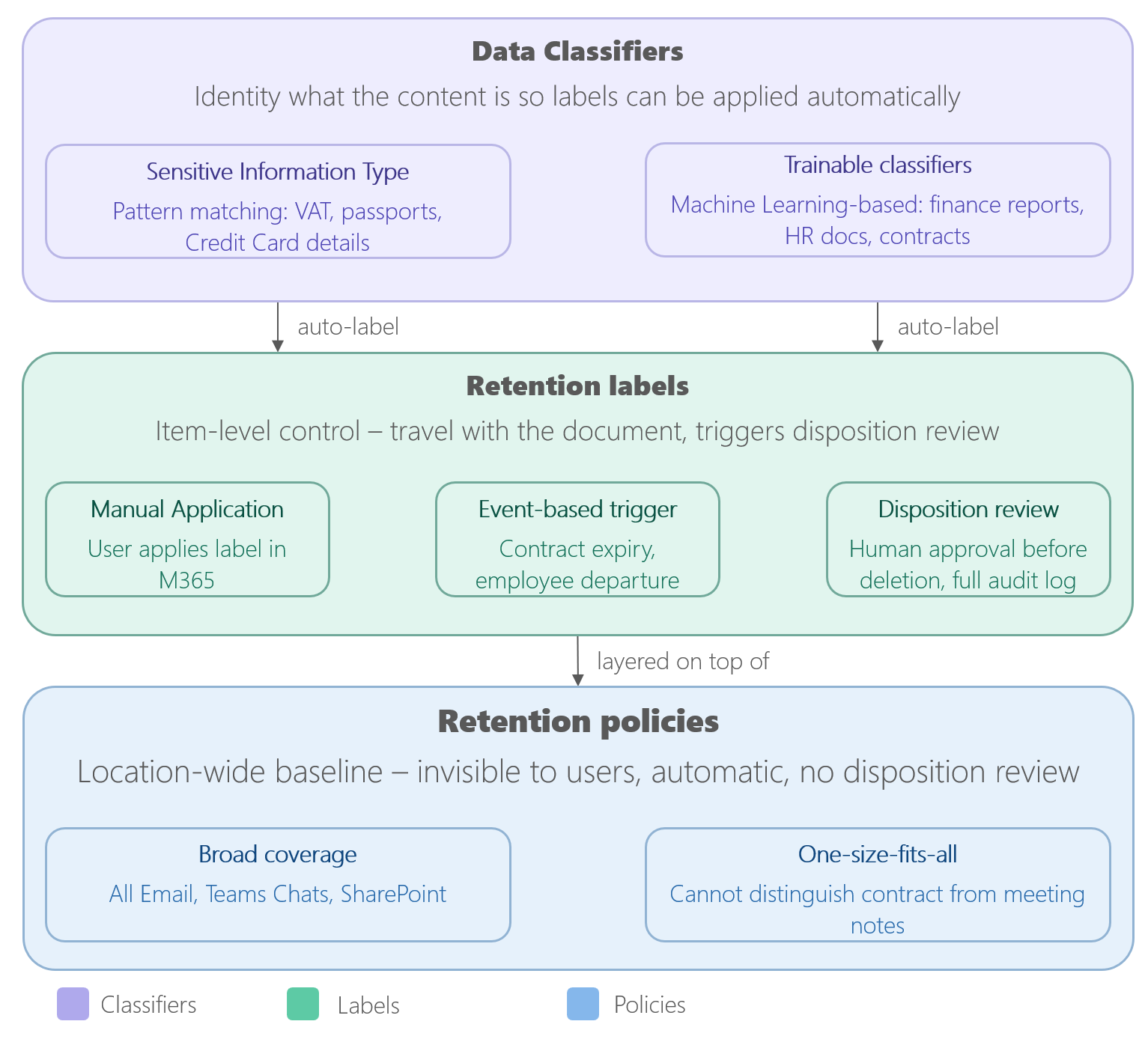
Retentiebeleid: het brede vangnet
Retentiebeleid is van toepassing op een enkele regel op een gehele locatie. “verwijder alle Teams chats na drie jaar”, “houd alle Exchange-e-mail vijf jaar.” Ze zijn onzichtbaar voor gebruikers en draaien automatisch op schaal.
Hun kracht is dekking. Hun beperking is dat ze one-size-fits-all zijn. Een bewaarbeleid kan geen onderscheid maken tussen een triviale vergadernota en een ondertekend contract. Het geldt dezelfde timer voor beide. En kritisch, retentiebeleid ondersteunt geen dispositiebeoordeling. Wanneer de timer verloopt, wordt de inhoud automatisch verwijderd, zonder menselijke controlepost.
My advies: Gebruik ze als basisprincipe. Gebruik ze om ervoor te zorgen dat niets voortijdig verdwijnt en niets voor onbepaalde tijd zonder reden wordt bewaard. Maar vertrouw niet op hen alleen voor iets dat oordeel vereist.
Retentielabels: gerichte controle en de beoordelingstrigger
Bewaarlabels worden toegepast op het niveau van het item: individuele documenten, e-mails, records. Ze kunnen handmatig worden toegepast door gebruikers of automatisch door het systeem. Ze reizen met het document, zelfs als het zich tussen sites verplaatst. Ze kunnen het vasthouden aan gebeurtenissen, zoals een vertrek van een werknemer of een contractverval.
Het belangrijkste voor de dispositie is dat retentielabels kunnen worden gebruikt om een verwijderingsbeoordeling te activeren. Wanneer de bewaartermijn voor een gelabeld item afloopt, kan Purview aangewezen beoordelaars op de hoogte stellen in plaats van automatisch te verwijderen. De beoordelaar ziet het item, kan het lezen en moet een beslissing nemen: verwijdering goedkeuren, de bewaartermijn verlengen, opnieuw labelen of escaleren naar iemand anders. Elke beslissing wordt geregistreerd. Niets verdwijnt zonder een bewuste keuze.
Dit is waar levenscyclusbeheer een kwaliteitscontrolediscipline wordt in plaats van een achtergrondtimer. Het is ook waar het zakelijke betrokkenheid vereist, wat teruggaat naar ons oorspronkelijke punt.
Data Classifiers: het krijgen van labels op de juiste inhoud
De praktische uitdaging met retentielabels is schaal - plane-and-simple. Je kunt niet elke gebruiker vragen om elk document handmatig te taggen. De meeste zullen dat niet doen. Sommigen zullen niet weten welk label van toepassing is. Velen zullen verkeerd labelen.
Purview addressert dit door middel van auto-labelling, aangedreven door ten minste twee classificatiemechanismen:
Sensitive Information Types (SITs) zijn op patronen gebaseerde detectoren. Ze bestaan uit ingebouwde regels voor zaken als btw-nummers, paspoort-id's, creditcardnummers of aangepaste zoekwoordpatronen die uw organisatie definieert. Wanneer Purview een match vindt, kan het het juiste bewaarlabel automatisch toepassen.
Trainable classifiers gaan verder. Je traint ze door voorbeelddocumenten te verstrekken die een categorie vertegenwoordigen - "financieringsrapporten", "HR-correspondentie", "voltooide projectbestanden" - en de classifier leert die inhoud op schaal te identificeren. Eenmaal getraind, kan het documenten van dat type in uw omgeving identificeren en deze dienovereenkomstig labelen.
Het praktische resultaat is dat de etiketteringslast van gebruikers naar het systeem verschuift. Gebruikers zien nog steeds labels die op hun inhoud zijn toegepast en ze kunnen ze waar nodig nog overschrijven - maar de standaard is geautomatiseerd, consistent en verdedigbaar.
Mijn advies: Voer altijd eerst automatisch labelen in simulatiemodus. Valideer dat de classifier de juiste inhoud tagt voordat je deze inschakelt. Een verkeerd gelabelde classifier die op schaal wordt uitgevoerd, zal meer werk creëren dan het opslaat.
Het probleem met algemeen retentiebeleid
Veel organisaties beginnen met een algemeen retentiebeleid. “Bewaar alles tien jaar in SharePoint.” Het is gemakkelijk te implementeren, gemakkelijk te rechtvaardigen om legaal, en produceert geen onmiddellijke wrijving. Het is ook een probleem dat zich rustig zal verergeren tot het moment dat je iets nuttigs probeert te doen met uw datalandgoed.
Hier is de structurele kwestie. Na tien jaar is het volume aan content dat verschuldigd is voor verwijdering enorm. Tientallen of honderdduizenden items, die allemaal op ongeveer hetzelfde moment aflopen. Zonder de zakelijke context om te begrijpen wat het allemaal is, kan IT geen zinvolle beslissingen nemen over wat te houden. De waarschijnlijke uitkomsten zijn ofwel de algemene verwijdering van alles, inclusief records die er nog steeds toe doen, of onbepaalde verlenging van de bewaartermijn, die het probleem behoudt in plaats van het op te lossen.
Geen van beide uitkomsten dient het doel. Je verliest kennis of houdt rommel. De verwijderingsbeoordeling wordt een betekenisloze oefening, omdat er gewoon te veel lawaai is om te isoleren wat belangrijk is.
Er is ook een compliance dimensie. Het bewaarbeperkingsprincipe van de AVG verbiedt uitdrukkelijk het bewaren van persoonsgegevens langer dan noodzakelijk. Een algemeen “houd alles” beleid, gehouden zonder zakelijke rechtvaardiging, is een aansprakelijkheid - geen vangnet.
De oplossing is niet om het algemene beleid te laten varen. Ze dienen een legitiem doel als vloer: een garantie dat niets vóór een minimumdrempel wordt verwijderd. Maar ze moeten worden gelaagd met gerichte bewaarlabels voor inhoudscategorieën die een andere behandeling vereisen, en die labels moeten in kaart brengen naar de delen van uw nalatenschap die daadwerkelijk een beoordeling rechtvaardigen voordat je wordt verwijderd.
Mijn advies: Disposition review moet de uitzondering zijn, niet de standaard. In de praktijk kunnen en moeten de meeste recordtypen bepaalde bewaartermijnen hebben met automatische verwijdering. Reserve disposition review voor de inhoudscategorieën waar een menselijk oordeel echt waarde toevoegt — contracten, regelgevingsinzendingen, strategische documenten. Het configureren van elk label voor beoordeling creëert vermoeidheid van de reviewer en verslaat het doel van het mechanisme.
Afsluitende gedachten
Tot nu toe hebben we het ‘waarom‘ en het ‘wat’ behandeld. Waarom AI van levenscyclusbeheer een probleem voor gegevenskwaliteitscontrole maakt, niet alleen een compliance-probleem. Wat Purview je geeft: bewaarbeleid als basislijn, labels voor gerichte controle. Auto-labeling vermindert de last voor eindgebruikers en ze zullen je daarvoor dankbaar zijn, maar alleen als dit correct wordt gedaan. Disposition reviews zetten zakelijk oordeel op het punt van verwijdering en dat is precies de reden waarom algemeen retentiebeleid met voorzichtigheid moet worden benaderd.
De draad die door alles loopt is verantwoording. Copilotengronden over wat toegankelijk is. Als het bedrijf eigenaar is van de gegevens, moet het bedrijf de beslissingen hebben over wat blijft, wat gaat en wanneer. IT levert de infrastructuur en de vangrails. Het bedrijf biedt de context en de laatste oproep. Geen van beide werkt zonder de andere.
Dat principe is eenvoudig te stellen. Het is aanzienlijk moeilijker om dit op Enterprise-schaal te operationaliseren. Dat is waar de volgende post oppikt. Als je meer wilt lezen over een praktische aanpak, blijf dan op de hoogte voor het volgende deel!